Autonomous Shopping Robot
Jul 2024 - Oct 2024
A fully autonomous robot capable of collecting items on a shopping list through heavy use of computer vision, SLAM and path planning.

The Autonomous Shopping Robot was made with a simple goal. Given a shopping list, find and collect all the items in the shortest amount of time without crashing into the supermarket environment. The list is random, the supermarket layout changes every time and the robot goes into the challenge with no human intervention. What follows is a lot of interesting maths, computer vision techniques and machine learning to navigate and identify fruits and vegetables in the supermarket.
Simultaneous Localisation & Mapping (SLAM)
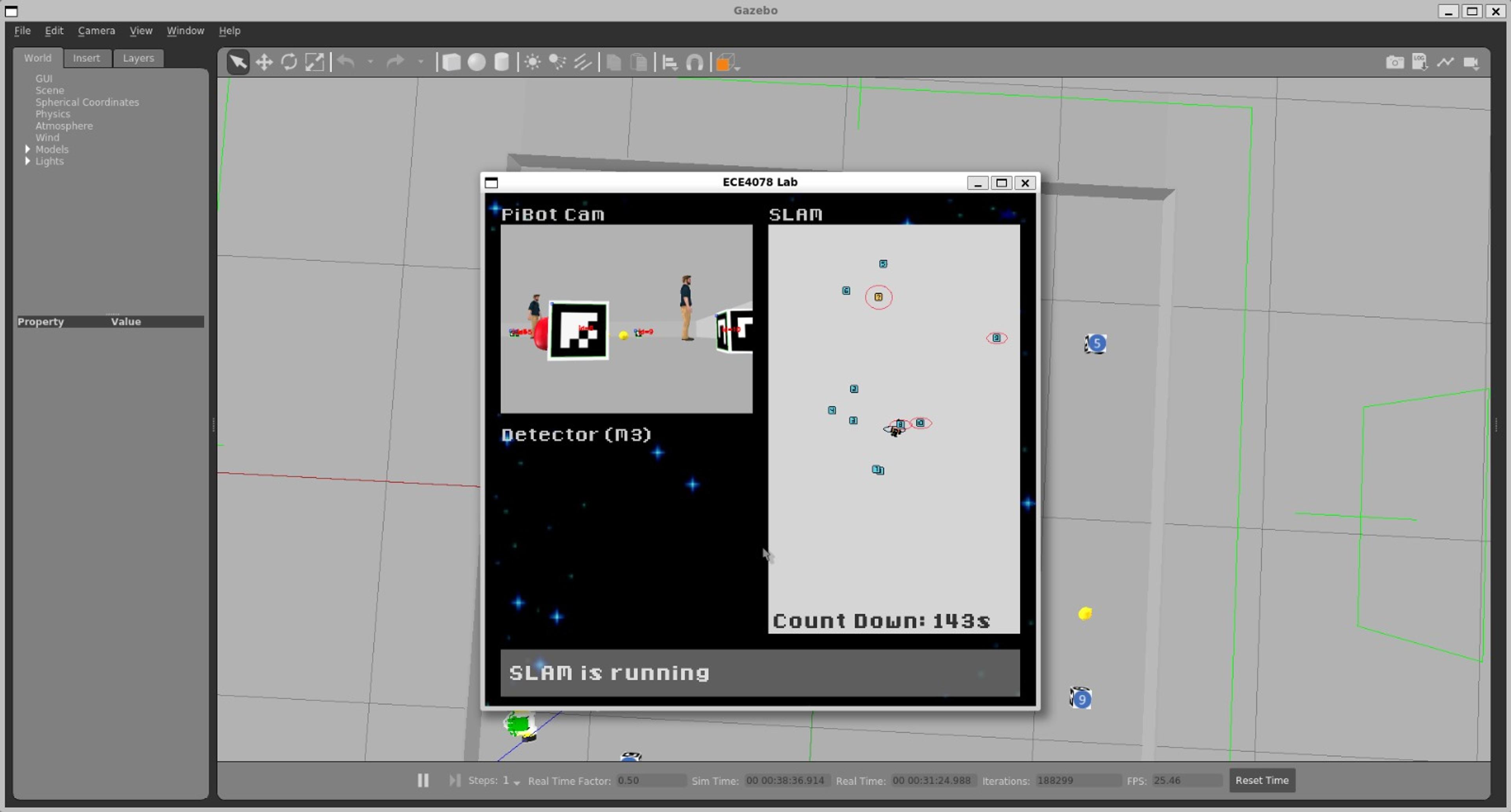
SLAM is the process of positioning yourself in the world while also mapping the world around you with a global source of truth. A combination of a physics model (predicting where the robot should be given a duty cycle applied to its motors over time) and sensors provide the information used to estimate where the robot is relative to the objects around it. In this environment, the ArUco markers and the target produce act as waypoints, although their pose and position needs to be determined at runtime. It's important to note that this robot is relatively simple. The only inputs it takes are left and right wheel velocities, and the only data it returns is the current camera view.
The state of our system is simply the position and rotation of the robot and the positions of each marker, . This represents all the information that we want to collect about the world through measurements and motion model predictions.
Our state also has an associated covariance matrix that tracks the join variability between each and every element in our state. It is initialised as a diagonal matrix, though it doesn't remain this way for long.
Modelling Motion
As previously mentioned, there are two parts to SLAM; the motion model and the measurements. We can ignore the ArUco markers for this part as they haven't grown legs yet. On the other hand, the robot can move. Given that the robot only has two wheels, the equations giving the motion model are quite simple. If the wheels are being driven at the same speed, we can assume linear motion with acceleration being negligible as the motors are electric and the period of acceleration is minimal compared to the time driven at speed. This effectively means that we can simply multiply the linear velocity by the time travelled to find the distance travelled. Mapping the linear velocity to the motor duty cycles is simply a matter of finding calibration constants (constants not constant as friction is a non-linear force) for difference linear velocities.
Where is the scaling factor and is the base width, the distance between the two wheels. Knowing the previous state , the control inputs and the time since the last measurement , we can model the motion of the robot.
When :
When :
These equations give a complete picture as to how the robot moves, in response to control signals given to the wheels. As each movement carries some uncertainty as our motion model doesn't account for every last physical interaction, we describe our state with a probability distribution. This distribution is modelled as normal distribution about with a configurable variance .
In practice we store and calculate the means and covariance separately, however the two combined fundamentally form the complete state.
Taking Measurements
Having already predicted where the robot is in the world, we can then use the camera to take measurements by reading ArUco markers. Oftentimes, this is a more reliable source of relative position, however, the absolute position of the markers is still unknown since we are mapping out the environment for the first time. There is also the fact that despite careful calibration, as the ArUco markers get futher away, measurements become less accurate, leading to the introduction of , a term denoting distance scaled uncertainty.
With these measurements, we can also convert coordinates in the world frame to the robot quite trivially:
Kalman Filters
The power of the Kalman filter occurs when we combine the motion model with the measurements to produce a better estimate than either one of these values alone. However, Kalman filters require a linear model, while our motion and measurement models are non-linear. This is not a problem as we can locally linearise each model at every time step to provide a close-enough approximation. This done by taking the first order Taylor series expansion (though high orders are possible too, but often not necessary). For this we simply need the first derivative at the previous state .
From here, we can compute the residual, i.e. the error between what we predicted vs what we measured. The residual covariance will dictate to what extent we trust our measurements when compared to the covariance of the existing prediction.
Finally, we obtain the last value, the Kalman gain .
Thus, we can apply our Kalman gain applied measurements to update the existing state and covariance matrices.
This process is completed continuously, in this case about 20 times a second continuous track and improve the information we gather about the world.
Target Detection
The identification of targets (i.e. fruits and vegetables) is completed through the industry standard object recognition and segmentation model, YOLOv8. The model was trained on 10,000 images of the fresh produce on a variety of backgrounds, however these images weren't manually labelled as this would be incredibly time consuming. Instead, a custom dataset generator was built to superimpose the fresh produce on a variety of backgrounds, while applying a variety of augmentations to improve the robustness of detections.

- Approximately 100 photos of the fresh produce were taken from the robot camera against a plain white background. Only the angle of the targets relative to the robot was varied in between shots.
- The backgrounds were automatically removed using a simple Python script, resulting in hundreds of labelled produce images with a transparent background.
- Various background photos were taken, ensuring that none of the images included the target. The produce images were superimposed onto these backgrounds, resulting image that resembled the authentic environment, except that the class and bounding box can be automatically assigned. While the images were superimposed, various augmentations were randomly applied, such as:
- Brightness
- Rotation
- Flipping
- Scaling
- Translation
- Blurring
- Hue-shifting
Once trained on these generated images, the model was incredibly reliable with >99% recall on an unseen test dataset and strong realtime performance in the trial environments.
Clustering & Pose Estimation
As explored earlier in the section on SLAM, we map out the produce as the robot drives around by combining estimates of the robots position and measurements taken from the camera feed. However, the next question that follows is how do we measure the relative position of the produce? Assuming fixed size produce, we can use similar triangles and the intrinsic matrix to find the distance and angle relative to the robot. This measurement can then be projected from the robot frame to the world frame to provide a position estimate for our produce.
Over time, we gather hundreds of unique estimates as to where a class of produce is, but this doesn't mean that there are equally many instances of this item in the real world. In fact, we may only have 1 or 2 pieces of garlic in a given space, but 300 slightly different position estimates. To resolve this, we employ DBSCAN clustering to group these estimates into a handful of usable positions.
